Explainable ontology matching for practical alignment runs
Install the system, prepare ontology inputs, run global or candidate-restricted
alignment, inspect evidence-level outputs, and serve the study visualizer.
Package
Python 3.10, Poetry
Main CLI
exact
Default scorer
PairAdaptiveSemanticScorer
Overview
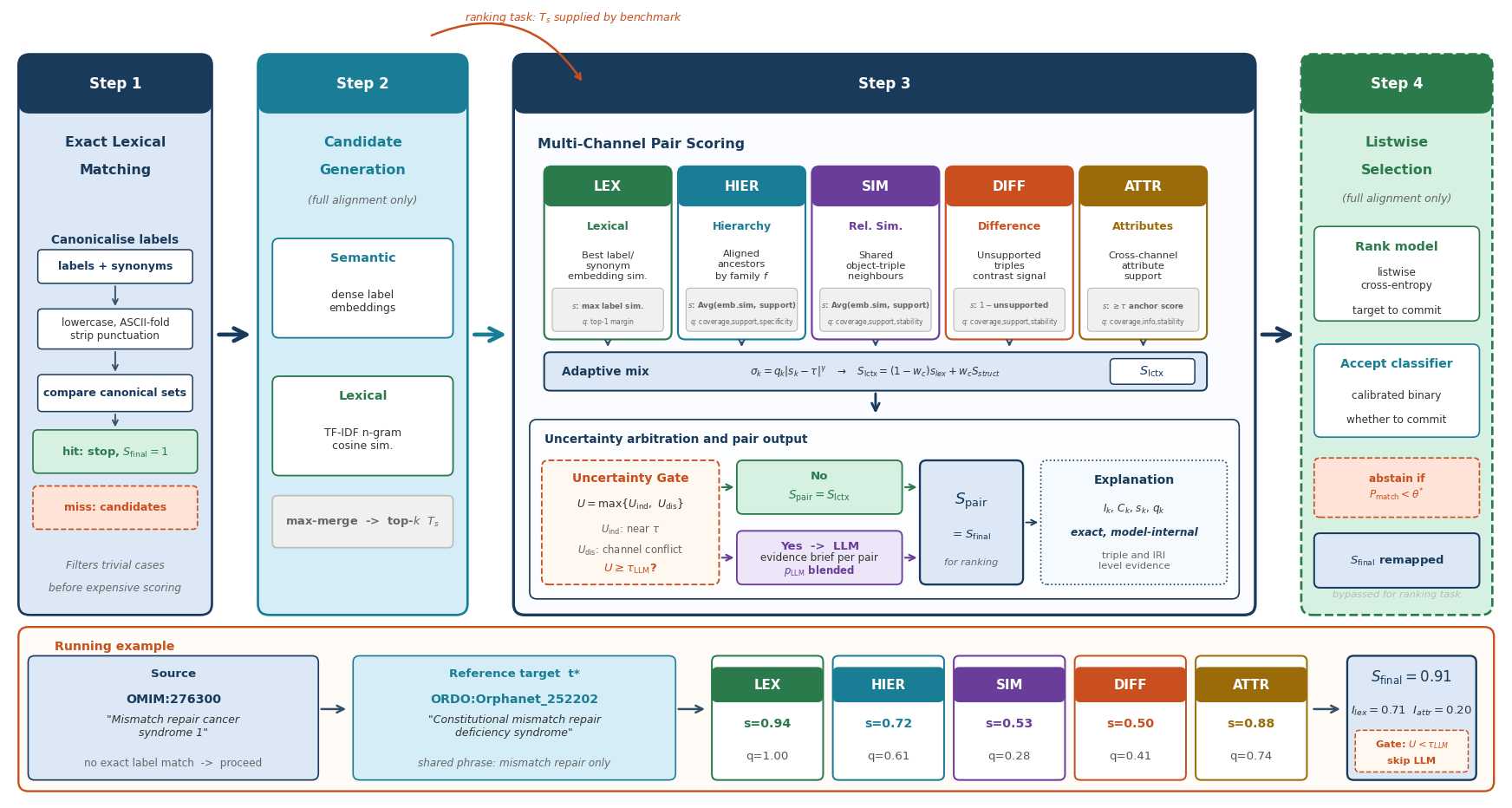
EXACT-OM predicts correspondences between source and target ontology entities.
It combines lexical label matching, ontology structure, auxiliary attributes,
optional LLM arbitration, and a global candidate selector. The important runtime
property is that each scored pair can carry an inspectable explanation: final
scores are broken down into lexical, structural, and LLM contributions, with
structural evidence split into hierarchy, similarity, difference, and attribute
channels.
Global mode
Use this when you want EXACT-OM to generate candidates, score them, apply threshold and cardinality filters, and write a mapping TSV.
Local mode
Use this when you already have a candidate TSV. Pass -c and the system keeps the full ranked target list for each source.
Audit and review
Enable summary and JSON outputs to inspect scores, channel importances, selected triples, rationales, and run statistics.
Install
Install from the repository root. Use Python 3.10 and make sure Java is available on the system path before running ontology-backed workflows.
poetry install
poetry run exact --help
Required: Python 3.10, Poetry, Java/JDK or JRE.
Recommended: CUDA-capable GPU for large biomedical runs.
Visualizer frontend: Node/npm only when rebuilding explanations_visualizer.
The package defines these entry points: exact,
bioml-eval, exact-llm-debug,
exact-user-study, and exact-study-viz.
Inputs
Every alignment run needs a source ontology, a target ontology, an output directory, and a YAML config.
Input
Required
Format
Used for
Source ontology
Yes
.owl
Source entity labels, annotations, hierarchy, and graph evidence.
Target ontology
Yes
.owl
Target entity labels, annotations, hierarchy, and graph evidence.
Training reference
No
TSV: SrcEntity, TgtEntity, Score
Supervised calibration for the global candidate selector.
Full reference
No
TSV: SrcEntity, TgtEntity, Score
Evaluation and reference-aware analysis.
Candidate file
No
TSV: SrcEntity, TgtEntity, TgtCandidates
Local ranking mode. TgtCandidates stores the target candidate list for the source.
The helper data/get_data.py downloads Bio-ML data when the
data directory is empty and can also build conference-dataset folders.
The repository keeps large dataset folders ignored, so expect to provide
benchmark data locally.
Run Alignment
Global alignment
Omit -c to let EXACT-OM build the candidate set and write a filtered global alignment.
YAML runtime configuration. Defaults to built-in settings when omitted.
-r, --training_reference_file
Optional training mappings for selector calibration.
-f, --full_reference_file
Optional reference mappings for evaluation and analysis.
-c, --candidates_file
Candidate restriction file. Enables local ranking mode.
-e, --run_eval
Run evaluation after writing the alignment.
-l, --save_logs
Write exact.log in the run directory.
-m, --jvm_heap_size
JVM heap size. A bare number is interpreted as GB.
-d, --device
CUDA device id. Omit for CPU.
YAML runner
For repeatable jobs, use a run-config YAML with tools/run_exact_job.py.
poetry run python tools/run_exact_job.py \
--run-config exp/runs/ncit_doid/run.yaml \
--dry-run
The same helper can submit through Slurm with --sbatch-script deploy/sbatch/exact_single_run.sh.
Configuration
The default config is exact/default_config.yaml. Copy it
into the run folder and edit only the blocks that matter for the run.
Small overrides are merged with defaults, so you do not need to repeat
every parameter.
Hosted decision scoring is probe-gated. If chat logprobs are unavailable, the runtime falls back to the configured local decision profile.
The most common first-pass tuning knobs are candidates_params.top_k,
alignment_params.threshold, dataset_params.n_hops,
dataset_params.hierarchy_max_depth, and
model.params.tau_LLM.
Exact lexical prefilter. Normalized labels and synonyms are matched first. Exact matches can be removed from downstream scoring and reinserted later.
Candidate generation. In global mode, a hybrid retriever combines dense label embeddings with lexical token and character similarity.
Pair-adaptive scoring. Each source-target pair receives lexical, hierarchy, similarity, difference, and attribute scores with quality estimates.
Adaptive fusion. Strong and reliable channels receive more weight. Empty channels become neutral and do not dilute the result.
LLM arbitration. Ambiguous or internally disagreeing pairs can receive a pair brief and a binary LLM decision probability.
Global selection. For generated candidates, the optional CandidateSetSelector compares each source's candidate set jointly and can abstain with NO_MATCH.
Audit export. Outputs include mapping files, flattened metrics, run stats, plots, and optional full explanation JSON.
Global evaluation reports precision, recall, and F1 against the reference alignment.
Local candidate evaluation uses the supplied candidate file and reports ranking metrics
such as MRR and Hits@K.
Additional analysis helpers include tools/analyze_alignment_run.py,
tools/aggregate_results.py, tools/run_candidate_recall_experiment.py,
and tools/run_cardinality_threshold_tests.py.
User Study Analysis
The exact-user-study command builds reusable artifacts from an
existing local ranking run. The run must contain
model/alignment/src2tgt.maps_local.tsv and
model/alignment/default/full_explanations.json.
Artifacts are written to <run-dir>/analysis/user_study unless --output-dir is set.
pair_metrics.csv and source_panels.csv: candidate and source-panel metrics.
study_shortlist.csv and study_selection_review.csv: balanced selection workflow files.
study_selected_records_with_rationales.json: final selected cases for the visualizer.
study_mapping.json: compact payload served by the study visualizer.
failure_taxonomy.csv and user_study_analysis.ipynb: failure-analysis outputs.
Study Visualizer
The visualizer serves a fixed study run through FastAPI and a static React/Cytoscape frontend.
It is designed for read-only inspection and LimeSurvey iframe embedding.
cd explanations_visualizer
npm install
npm run build
cd ..
poetry run python -m study_visualizer_runtime.cli \
--run-dir exp/runs/omim_ordo/local \
--analysis-dir exp/runs/omim_ordo/local/analysis/user_study \
--port 8000
Open a specific source panel with:
http://localhost:8000/?source=<exact_source_iri>
Render bundle deployment
For a lightweight hosted visualizer, export a bundle and deploy the Render assets in deploy/render.